Reflections on Hardware-Software Co-Design in ECE
This article is AI-generated by Gemini 3.5 Flash! I am currently using this as a formatting guide for other articles.
As modern computing hits the limits of classical silicon scaling, the path forward has increasingly shifted away from general-purpose CPUs toward highly specialized domain-specific architectures (DSAs). In my PhD research in Electrical and Computer Engineering at UIUC, I focus on the interface where hardware meets software—specifically, compilers that can translate high-level algorithmic logic into representations that run optimally on hardware accelerators.
The Gap in Toolchains
Historically, hardware developers and compiler engineers worked in separate silos:
- Hardware designers modeled circuits using RTL (Verilog/VHDL), aiming for low area, high frequency, and efficient thermal dissipation.
- Software developers wrote standard C/C++ or high-level frameworks (like PyTorch), relying on compilers to generate machine instructions.
With specialized accelerators (e.g., Systolic Arrays, TPUs, custom Neuromorphic chips), this separation breaks down. The compiler cannot treat the hardware as a simple, sequential processor. It must coordinate memory hierarchies, parallel ALU configurations, and asynchronous data movements explicitly.
Visualizing the Hardware Bus
To optimize data paths, we model the physical layout of processor cores alongside DRAM modules. Below is a high-level schematic of a multi-core processor bus interface that we target in our compilation passes:
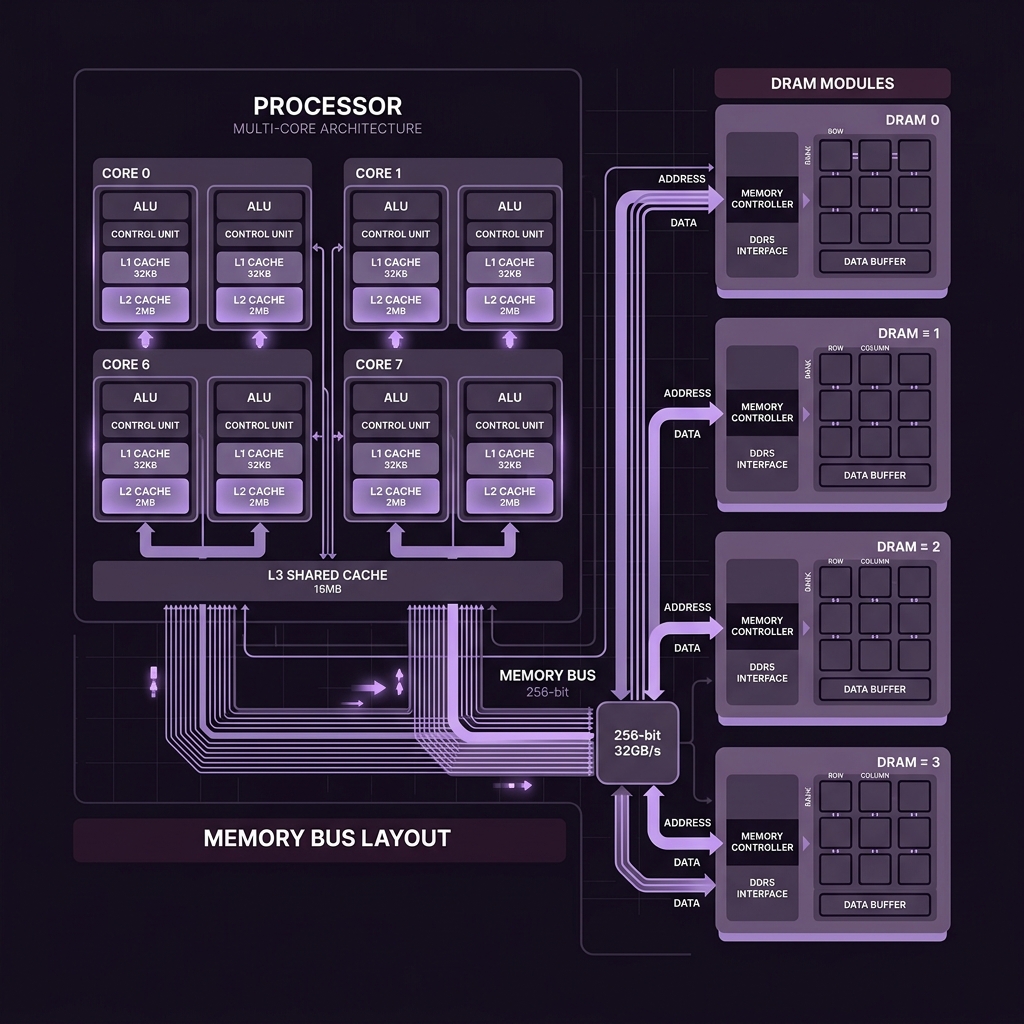 Figure 1: Multicore processor architecture and DDR5 memory bus interface structure.
Figure 1: Multicore processor architecture and DDR5 memory bus interface structure.
Research Agenda: Intermediate Representations (IR)
Our group is currently exploring how MLIR (Multi-Level Intermediate Representation) can be utilized to model these specialized memory and execution behaviors.
By defining dialets tailored to specific accelerator features, we can perform optimization passes (such as loop tiling and array buffering) directly on high-level representations, before lowering the instructions down to hardware-specific machine code.
// Example of a conceptual compilation pass logic
struct LoweringPass : public PassWrapper<LoweringPass, OperationPass<ModuleOp>> {
void runOnOperation() override {
auto module = getOperation();
// Transform custom high-level tensor operations into targeted hardware instructions
module.walk([](CustomTensorOp op) {
if (canVectorizeOnHardware(op)) {
applyHardwareVectorization(op);
}
});
}
};
Moving Forward
Looking ahead, we are aiming to evaluate our IR optimizations on FPGA prototypes and custom emulator backends. By bridging the gap between high-level compiler optimizations and physical hardware design, we can extract orders of magnitude better energy efficiency—a critical parameter for the future of scalable computation.
Project Publications & Reports
For a detailed analysis of our compilation pass timings, refer to our recent project whitepaper embedded below: